
Introducing Autopilot
Today, we’re launching Autopilot: Cleo’s first step toward autonomous money management.
Closed

When we launched Cleo 3.0 last summer, we introduced our first AI agents: one that reasoned through conversations in real time, and one that analyzed transactions in the background. That architecture let Cleo do things she couldn’t before, including looping through tools to complete multi-step tasks in a single chat and proactively identifying financial insights.
Now, we’re expanding what Cleo’s agentic architecture can do. The conversational side is a team of domain-specific specialists, with a router classifying each incoming message and a handoff protocol enabling specialists to redirect conversations to each other as needed. On the background side, our asynchronous agents can now create a persistent financial profile of each user that the conversational agents can draw on when they respond in chat.
By “multi-agent architecture,” we mean a system of specialized agents, each with its own scope and tool set. They connect through three mechanisms: a router that classifies incoming messages, a handoff protocol that lets one agent redirect a conversation to another, and sub-agents that appear as tools inside other agents.
An AI assistant that helps people manage their money has to do various jobs, including interpreting messy transaction data, understanding long-term spending trends, generating personalized insights, and holding real-time conversations. These jobs have different context windows, latency budgets, reasoning patterns, and data needs.
In principle, a frontier model could handle a large, complex prompt describing many of these jobs at once. But in practice, a mega-prompt that covers everything Cleo does accumulates redundancy and internal conflicts. Small changes can have unexpected ripple effects, and each improvement risks regressing something else. Splitting the work across smaller, scoped agents lets us evolve each one independently.
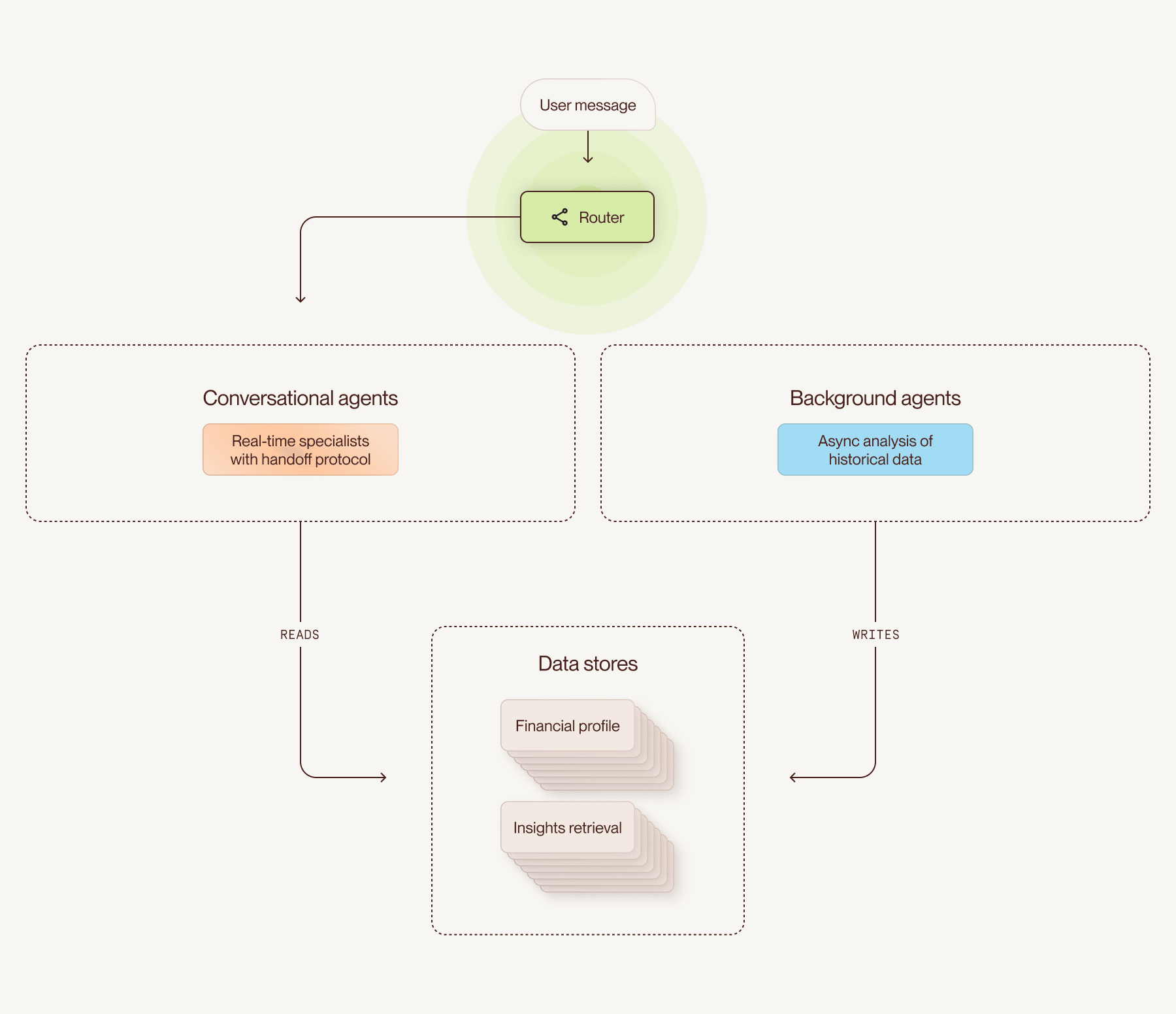
A router sends each user message to a conversational specialist, which can read from data stores that background agents populate by analyzing historical data.
Splitting also enables us to match the compute to the task. Conversational agents need to be fast, given that a chat turn has to complete in seconds. Consequently, they run on lighter models with short prompts and a narrow set of tools, which has the added benefit of improving tool-calling accuracy.
Analytical work, on the other hand, benefits from heavier models and longer runs. Building a picture of a user’s finances over the previous year can involve thousands of tokens of model output and multiple chained LLM calls, while a single-prompt configuration would force a choice between depth and speed. Splitting lets us have both.
Routing also makes Cleo faster. When the router sends an incoming message directly to one focused specialist, that specialist runs on a shorter prompt with a narrower toolset than a general-purpose agent would. It picks tools more accurately, starts generating a response sooner, and can run on a lighter-weight model when the task allows.
The same split lets us improve agents in isolation. Our current migration from GPT-4.1 to GPT-5.4 is illustrative: We can roll the change out behind A/B tests on specific agents, observe those conversations, and broaden exposure from there. When we add a new capability, we can build or upgrade one agent without reevaluating the entire configuration.
In practice, we build the agent structure iteratively. A domain becomes a candidate for a dedicated agent when the task is clearly defined and the work aligns with current product priorities. From there, we can split, observe, and use what we learn to inform the next split. This bottom-up approach avoids premature abstraction and keeps the architecture tracking the product rather than the other way around.
Conversational agents are the part of Cleo users interact with directly, although it feels like one continuous conversation from the user’s side. Behind the chat interface are multiple specialists, selected based on what topic the user brings up.
They operate under shared constraints. Chat turns need to complete quickly, which puts a tight latency budget on each agent and pushes us toward lighter-weight models. Context windows stay narrow, as each exchange is limited to the live conversation, not the user’s full financial history. Output is also constrained: The mobile app can’t show pages of model-generated reasoning, and each token the model generates is a token the user is waiting on, even if we hide it. Thus, conversational agents get small output budgets alongside small input prompts.
Users’ conversations cluster into several domains. For example, we’re implementing a dedicated agent for earned wage access, a high-traffic area with a well-defined set of tasks such as checking advance status, setting up repayment, and managing the associated subscription. Grouping related tasks under a single specialist keeps the boundaries clean and makes routing among agents manageable.
Agent selection currently happens through two complementary mechanisms. The first is a classifier that routes each incoming message to the right specialist. Today, that’s an LLM call; we’re replacing it in the coming weeks with a dedicated router model, which is fast enough that the routing decision disappears into the latency of the chat turn itself.
The second mechanism is a handoff protocol. A select_new_agent tool lets a specialist redirect a conversation if the request belongs to another agent. If someone asks the EWA specialist about spending trends, for instance, it can hand off to an agent better suited to that question rather than try to answer with the wrong toolset. We’re also beginning A/B testing on a hybrid selection mechanism that combines the router with handoff, to catch cases where the initial classification turns out to be wrong as the conversation unfolds.
While conversational agents handle the live chat, a separate set of agents works behind the scenes to reason deeply about a user’s financial situation. Background agents run on a longer time scale than any single chat session, building a comprehensive picture of a user that real-time chat alone couldn’t.
This split is what makes deep analysis possible in the first place. Understanding a year of someone’s transactions—including their cash flow, pay cadence, recurring obligations, months in which they ran a deficit, and whether they have a savings cushion—is the kind of work that benefits from a capable model and plenty of time. The input alone is substantial, consisting of a full year of transactions plus enrichment data that helps the model make sense of them.
Alongside the final structured output, reasoning models produce extensive internal reasoning to build that kind of picture. The tokens in that output can reach into the thousands as the model works through the data and checks itself for consistency. Moreover, we often chain multiple LLM calls together, each handling a different step of the analysis. By separating this work from real-time chat, we can afford to spend the time and compute it takes to get the analysis right. The output is stored and made available to the conversational side at the moment it's needed.
The first place this work lands for users is onboarding. When someone connects their accounts for the first time, Cleo doesn’t wait for them to ask questions. She uses the time during setup to analyze their data and surface observations that are specific to them, so that by the time the first conversation begins, she already has something to say. For instance, she might note that a user’s income has grown steadily over the past year while their savings have remained flat.
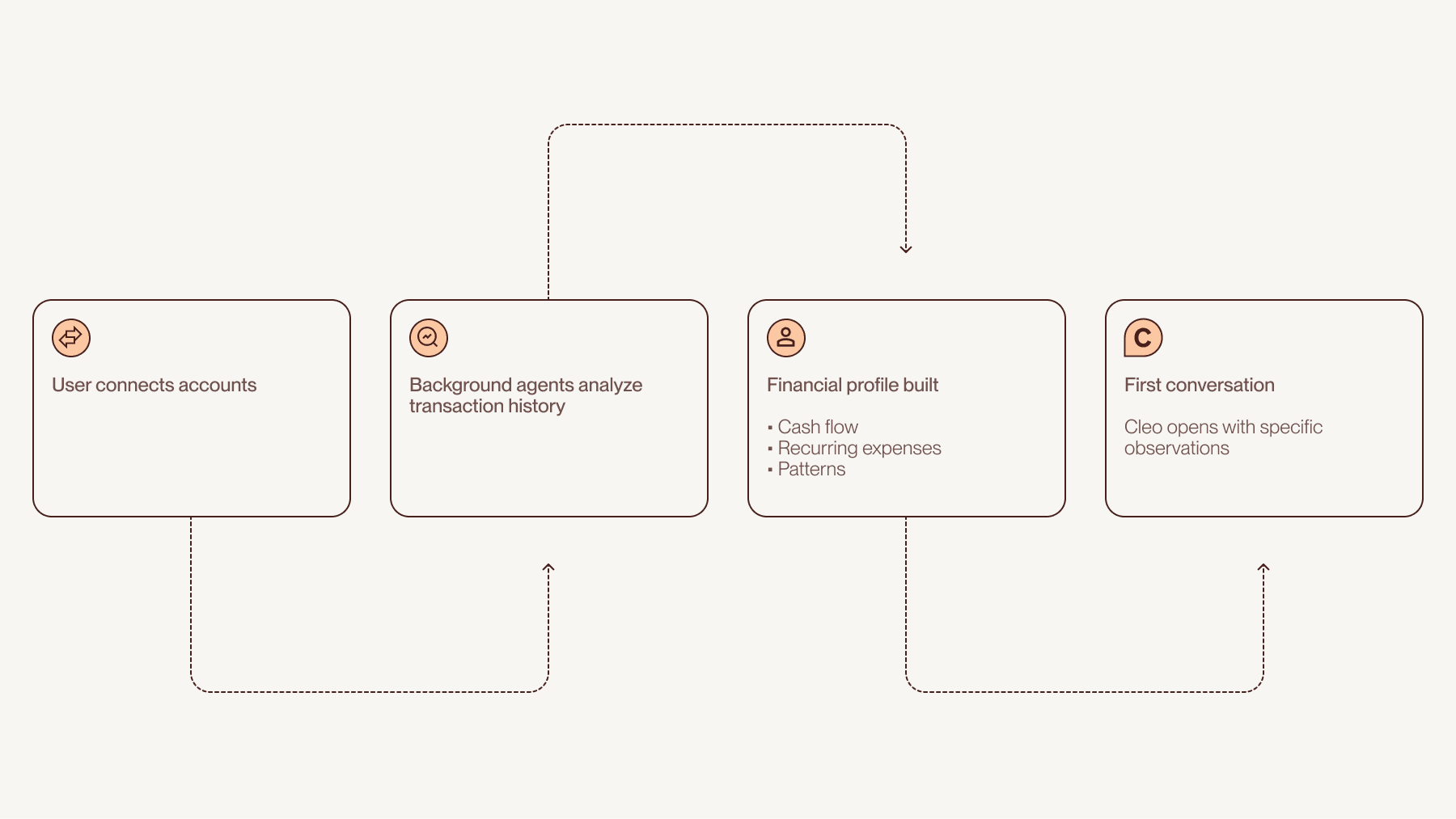
When a user connects their accounts, background agents analyze transaction history and build a financial profile, so Cleo can open the first conversation with personalized insights.
The two agent types are designed to complement each other, and they connect through a small set of stable data stores. The financial profile data store holds the structured picture of a user’s finances that the background agents have built. A separate insights retrieval endpoint identifies the specific behavioral insights most likely to resonate with a given user in the moment.
Conversational agents read from both, either at predetermined stages in their workflows or dynamically through tool calls. If a user asks why their March spending felt high, for example, the conversational agent doesn’t need to parse months of transactions on the fly. Instead, it can query the precomputed financial profile and quickly find that that month’s spending was higher than the user’s monthly average, driven mostly by dining out.
The two modes let Cleo operate on two time scales at once. Conversational agents respond in seconds, while background agents take as long as they need to produce the structured picture of the user the conversational side draws on. Because the two modes are decoupled, we can iterate on each without disturbing the other. That means we can add new specialists, swap in a new model, or extend what the background analysis covers without rebuilding what already works.
Today, we’re launching Autopilot: Cleo’s first step toward autonomous money management.

When extending Cleo’s chat engine to real-time voice, we needed to keep Cleo’s personality and tone while maintaining high accuracy and low latency.

Cleo’s quick replies only help if they arrive before users start typing, so we fine-tuned a specialized small model to reduce latency.

It’s part of a larger system that keeps message classification accurate as user behavior shifts and new agents come online.