
Introducing Autopilot
Today, we’re launching Autopilot: Cleo’s first step toward autonomous money management.
Closed

We’re launching a new router for Cleo, a custom model built using our own conversational data. Cleo’s conversational layer is a collection of specialized agents, each handling a slice of what users talk to Cleo about. The router is the component that decides which specialist agent fields a given message, quickly enough that users don’t notice the extra step.
The router we’re shipping today is an encoder-only model trained on Cleo’s conversational traffic. It runs classification roughly 16× faster than the LLM-based router it replaces and beats GPT-5.4-nano on accuracy against our internal benchmarks. Training directly on real Cleo conversations is what gives the in-house model its edge. The classifier learns to recognize the specific kinds of messages users send to Cleo, which a general-purpose model can’t do.
Cleo’s router is a classification layer. Incoming messages pass through it, and the router decides which specialist agent should handle the reply before generation happens. Speed is a design constraint, as any latency the router adds directly affects how long a user waits for Cleo’s response.
Each routing decision is made before an agent starts replying, so switches between specialists don’t interrupt a response in progress. The system also assumes, correctly, that any classifier will occasionally be wrong. When a specialist receives a message better suited for a different specialist, it can call a handoff tool to pass the message to the correct agent, so an incorrect initial classification doesn’t force the user to restart the conversation.
The version of the router running on GPT-5.4-nano had a latency of roughly 800 ms per message. The replacement is a custom encoder-only model, trained on data from Cleo’s own conversational traffic and shaped around our agent taxonomy. It runs at around 50 ms, a 16× latency reduction.
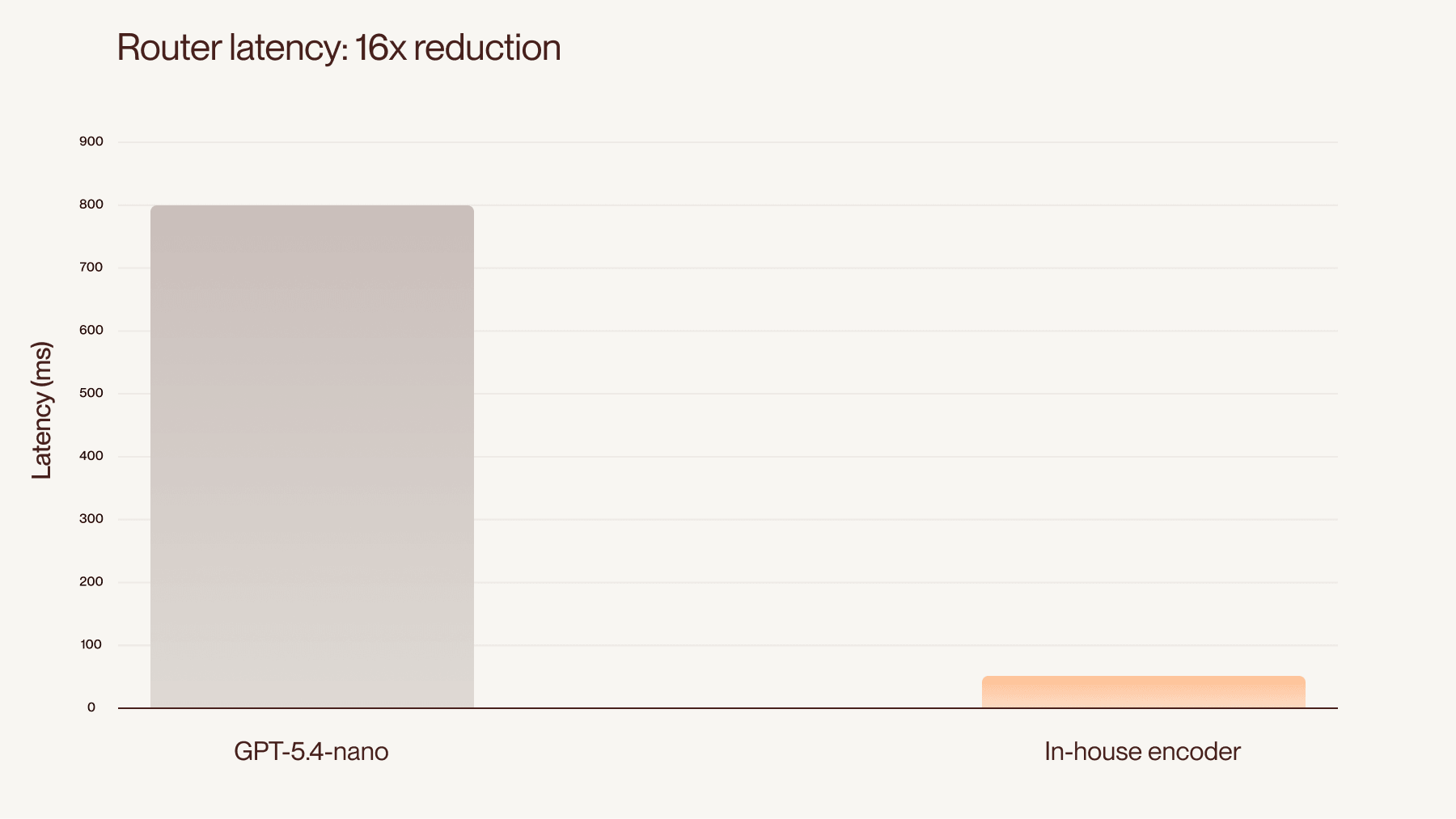
Comparison: GPT-5.4-nano vs. in-house encoder model.
Measuring router accuracy well requires more than one offline benchmark. We evaluate against two labeled data sets that answer different questions:
The first is a human-annotated set of tool call scenarios where labels are direct: For a given message, did the router send it to the agent whose tools match the request? On that data set, accuracy is around 94%.
The second set is broader, drawn from conversations that human reviewers have flagged as high quality. The labels here are less direct; we use overall conversation quality as a proxy for tool call accuracy. That gives us a noisier signal, but one we can apply to far more conversations. Accuracy on that data set is approximately 92%.
Most of the errors on the broader data set are not misrouting per se. Rather, they’re cases where the router made a defensible call (the conversation was clearly inside one domain), but the user’s most recent message introduced something that domain’s agent wasn’t equipped to handle. In such cases, the fix is usually to widen the agent’s tool scope.
Four pieces of infrastructure let us keep upgrading Cleo’s router as models, architecture, and user behavior change.
The primary router serves live traffic. A shadow model runs in parallel against the same conversations, making routing decisions the user never sees. Comparing the two streams shows us exactly where the primary model makes mistakes against the shadow’s predictions, which feeds back into the training data for the next round.
Running against user traffic enables us to respond to shifts in the mix of user messages over time. A benchmark built in January can’t always tell us whether the router is making good decisions on the conversations people are having with Cleo in April, for example, due to changes like a new feature or shifts in user queries. Traffic mirroring anchors our evaluations in real production traffic rather than a static snapshot.
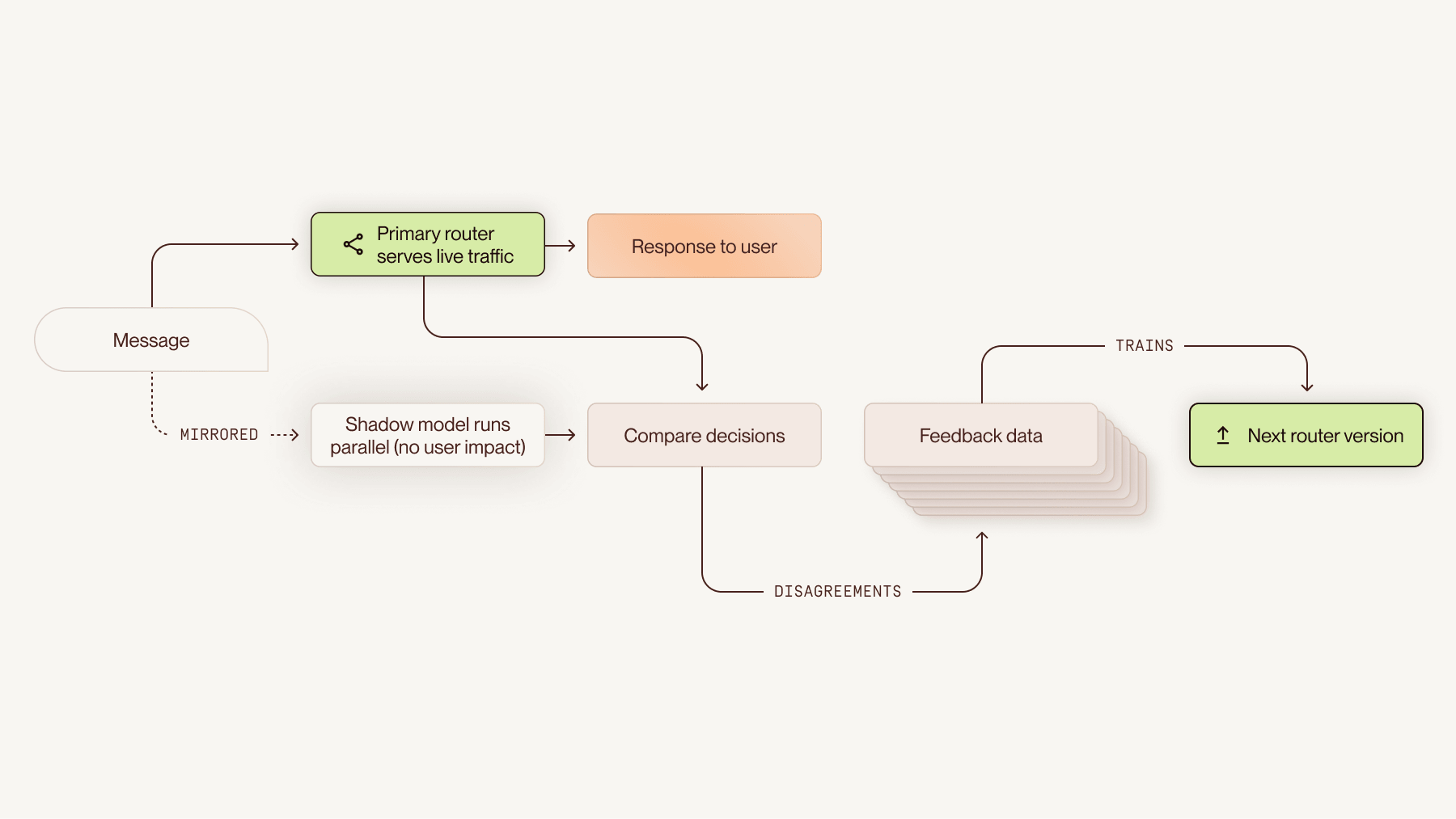
How we use traffic mirroring to train the next router.
As a manual loop, improving an agent’s prompt requires an engineer to look at failure cases, rewrite part of the prompt, deploy it, wait, look at the new failure cases, and repeat. To automate that loop, we feed in the current prompt, a data set of real conversations and their outputs, and human-annotated (and sometimes LLM-judged) evaluations of those conversations.
From that input, we can generate candidate prompt revisions aimed at the specific failure modes the evaluation data exposes. Engineers then review and test the proposed revisions to decide what ships. Template variables remain intact throughout the optimization, so the process changes how the agent reasons within its domain without altering what data or tools it can access.
Two layers of evaluation run in parallel. Offline evaluation focuses on tool selection, or whether the router picked the right specialist for a given input. It runs against the human-annotated tool call data set and the broader reviewer-flagged set. Online evaluation runs during rollout. Both human reviewers and LLM judges annotate a sample of real conversations, flagging drift and edge cases missed by offline benchmarks.
Major changes, such as bringing a new specialist agent online or migrating to a new underlying model, go through a two-phase test before reaching all users. The first phase is an A/A test. The updated system is deployed with prompts and tools identical to the current one to isolate the impact of any infrastructure changes on engagement and conversion. Only once that passes does the A/B test go live with the actual behavioral change. Both phases run as gradual rollouts, monitoring for engagement, conversion, and conversation quality.
This is the pattern we’re using to migrate Cleo’s conversational agents from GPT-4.1 to GPT-5.4. Prompt wording, tool schemas, and parameter settings can all behave differently under a new model and have to be retuned before live traffic routes through the updated stack. We run offline optimization across configurations, identify the combinations that perform well, and A/B test the winners against the current production system.
We’re working on several future directions that build on this foundation:
Complexity-based routing. Today, the router picks a specialist agent based on message topic. A natural extension is to choose a specialist based on both topic and complexity, so lighter models handle simple requests and reasoning models handle more involved ones.
In-house small language models. In addition to our in-house encoder, we’re building other Cleo-specific models for routing and for some specialist tasks. By building small models internally, we can optimize directly for the distribution of conversations Cleo actually sees, rather than relying on general-purpose models.
Tighter feedback loops. Traffic mirroring already produces the data used to train the next router version. The next step is to tighten that loop so that less time elapses between when the shadow model flags a mistake and when that data reaches the next training run.
Today, we’re launching Autopilot: Cleo’s first step toward autonomous money management.

When extending Cleo’s chat engine to real-time voice, we needed to keep Cleo’s personality and tone while maintaining high accuracy and low latency.

Cleo’s quick replies only help if they arrive before users start typing, so we fine-tuned a specialized small model to reduce latency.

Specialization lets us match the right agent to each task.