
Introducing Autopilot
Today, we’re launching Autopilot: Cleo’s first step toward autonomous money management.
Closed

Bank transaction descriptions don’t follow a universal standard. The same coffee shop might appear as SQ *BLUE BOTTLE or BLUBTTLE NYC, while a Venmo payment to a friend is structurally identical to a Venmo payment to a landlord. Subscriptions and installment plans both recur monthly; income and reimbursements both arrive via ACH.
Cleo users connect their bank accounts via open banking, which means we receive transactions in whatever form their bank provides. Unlike a card issuer or bank, we don’t have access to richer merchant data at the point of sale. We’re working with the same sparse records a user sees on their statement.
Rule-based classification systems can handle obvious cases, but much of the time, real meaning is dependent on context. Cleo needs that context to be able to reason over a user’s full financial picture, including recurring bills, income streams, and spending distribution across categories.
Cleo’s legacy system used a transaction taxonomy that wasn’t fit for purpose. The architecture had also grown organically, with logic scattered across the codebase, making iteration and scaling difficult. These limitations weren’t acceptable for a product that relies so heavily on reasoning about transactions.
Our latest release, Autopilot, depends on understanding users’ financial lives with precision: what they earn, what they owe, which expenses recur and which don’t. That requirement motivated a rebuild of our transaction enrichment foundation.
When a raw bank transaction arrives, it typically includes a description string, a date, an amount, and an account identifier. Cleo’s enrichment system transforms these raw records into structured, queryable data.
Every enriched attribute also comes with a confidence score explicitly quantifying the system’s uncertainty. This enables intelligent downstream behavior: Autopilot can select the highest-confidence income stream when multiple candidates exist, for example, rather than arbitrarily picking the first one or requiring users to manually validate everything.
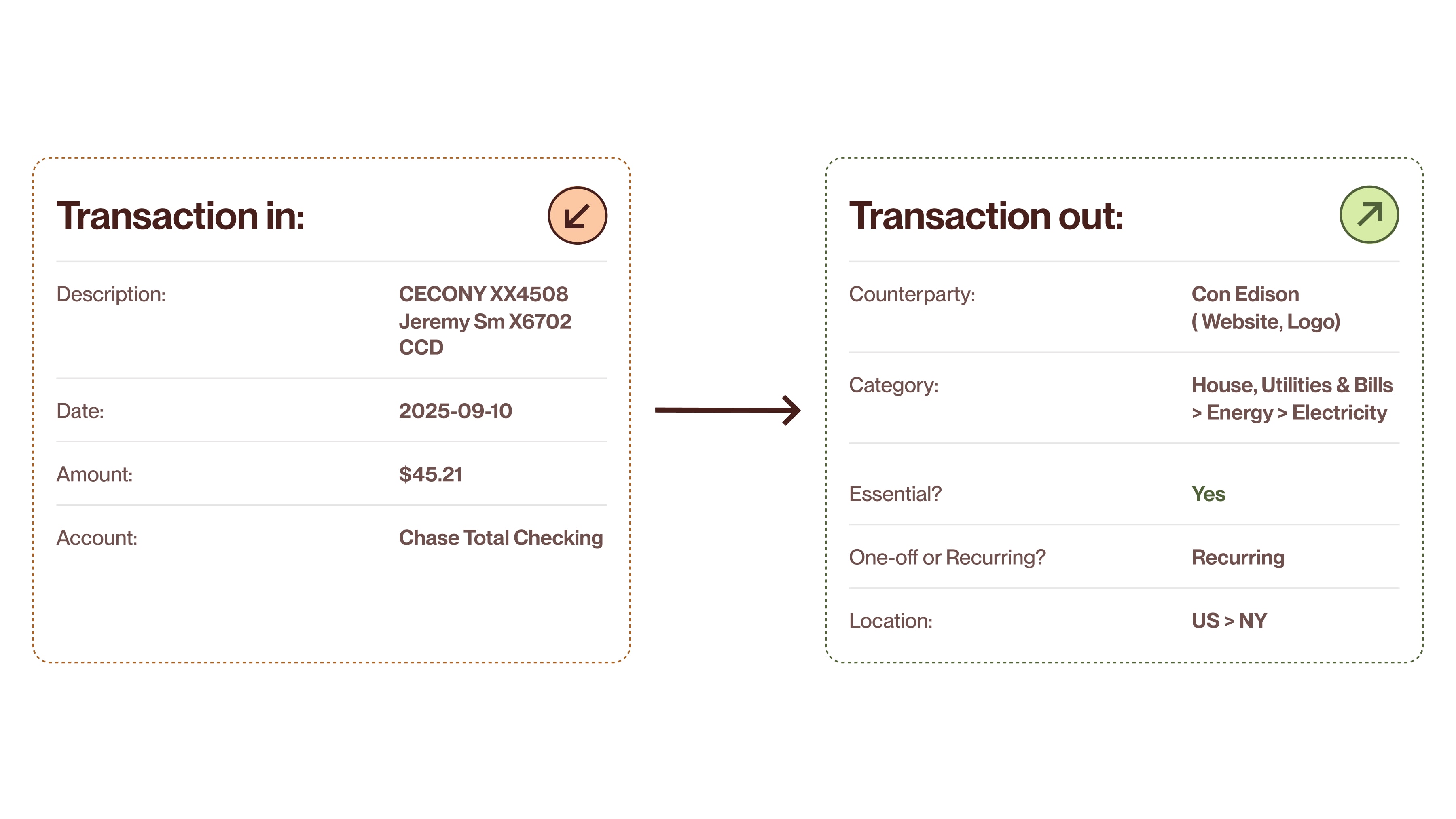
A realistic example of raw vs. enriched transaction data. A cryptic description becomes a structured Con Edison electricity bill, categorized hierarchically, marked as essential and recurring, and geolocated to New York.
A single transaction gains multiple layers of context:
Counterparty identification. The system resolves cryptic transaction descriptions to actual businesses (e.g., Amazon, payroll provider), attaching metadata like the merchant’s website and logo.
Hierarchical categorization. Transactions are classified into a two-level taxonomy with 19 top-level categories and approximately 175 total items, rather than flat categories. So an electricity bill doesn’t just land in a “Utilities” bucket; it’s categorized as Housing, Utilities & Bills → Energy → Electricity.
This hierarchy lets downstream systems reason at whatever level of granularity they need. Autopilot might care about total utility costs for budgeting purposes, for example, while a response to a user question about their recent spending breakdown might need to distinguish between electricity and phone bills.
Essential vs. non-essential. Each transaction is flagged based on whether it represents a necessary expense or discretionary spending. The definition is grounded in in-house labeled data, with “essential” meaning necessities such as housing, food, healthcare, and utilities.
The prediction is primarily description based, but when that confidence is low and category confidence is high, the system can infer essentiality from the category itself. This fallback captures cases where the description is ambiguous, but the spending type is clear.
Recurring vs. one-off. The system identifies whether a transaction is part of a recurring pattern. This requires going beyond labeling discrete records, instead analyzing sequences of transactions to identify income streams and regular commitments over time.
Location. Where applicable and possible, transactions include geographic data.
Cleo’s approach (which we internally call the Swiss cheese model) balances accuracy with latency and cost by layering multiple classification strategies, each catching what the previous layers miss. Any one layer has holes, but stack enough slices, and very little falls through.
Tree-based models. The first layer applies fast, lightweight tree-based models. These handle common patterns efficiently, focusing on the kind of classification that requires pattern matching on known features rather than in-depth linguistic understanding.
Fine-tuned small language models. When tree-based approaches lack confidence, the system escalates to fine-tuned SLMs. These models handle more nuanced classification, such as parsing ambiguous descriptions or disambiguating similar merchant types, while remaining fast and cheap to run.
Frontier LLM fallback. Only when all previous layers fail to produce a confident classification does the system call a frontier LLM (roughly once in every 10,000 transactions). Reflecting how well the earlier layers perform, the LLM serves as the backstop, ensuring that maximum capability is reserved for maximum difficulty.
The architecture was originally designed to include a cache layer for exact-match descriptions, but local model latency proved fast enough to make it unnecessary; the models now outperform cache lookup. The result is a classification system that’s both accurate and cheap enough to run on every transaction in real time.
Supervised learning requires labeled data, but labeling transaction data at scale is expensive and slow. Moreover, financial transaction data carries additional constraints, such as sensitivity around PII and the sheer volume required to cover the long tail of merchant types.
Cleo’s solution uses a technique common in modern ML pipelines, namely using a high-capability model to generate training data for smaller, more efficient models. The implementation has four stages:
Golden set. The foundation is a hand-labeled data set covering the complete transaction history for a small group of users. Every transaction was reviewed and categorized according to the new taxonomy through collaboration between the user who made the transaction—and therefore knows exactly what it was for—and a domain expert. This pairing produces unusually high-quality ground truth by eliciting verified real-world intent, which is then validated by someone who understands the taxonomy. The golden set serves as the benchmark against which all subsequent models are measured.
Oracle. With evaluation criteria established, the next step is to build the best possible classifier regardless of cost or latency. This model, which we internally refer to as the oracle, combines frontier LLMs with web search and any other resources that improve accuracy. The goal is a reference implementation that helps us understand how good we can get.
Silver set. The oracle then labels a much larger volume of transaction data, producing what’s called a silver set. These labels aren’t verified by hand but are generated by the highest-capability system available. The silver set serves as training data for the production models, transferring the oracle’s capabilities to smaller, faster models.
Production models. The tree-based models and fine-tuned SLMs described in the previous section are trained on the silver set, then evaluated against the golden set. In this way, the oracle’s expensive inference happens once, during training data generation, and is then amortized across production classifications.
The system also requires ongoing monitoring to address model drift, new merchant types, and other changes in the transaction landscape. Rather than continuously expanding the hand-labeled golden set, we implemented an LLM-as-judge approach. A frontier model evaluates classifications on new, unseen transactions, providing a performance signal without manual annotation.
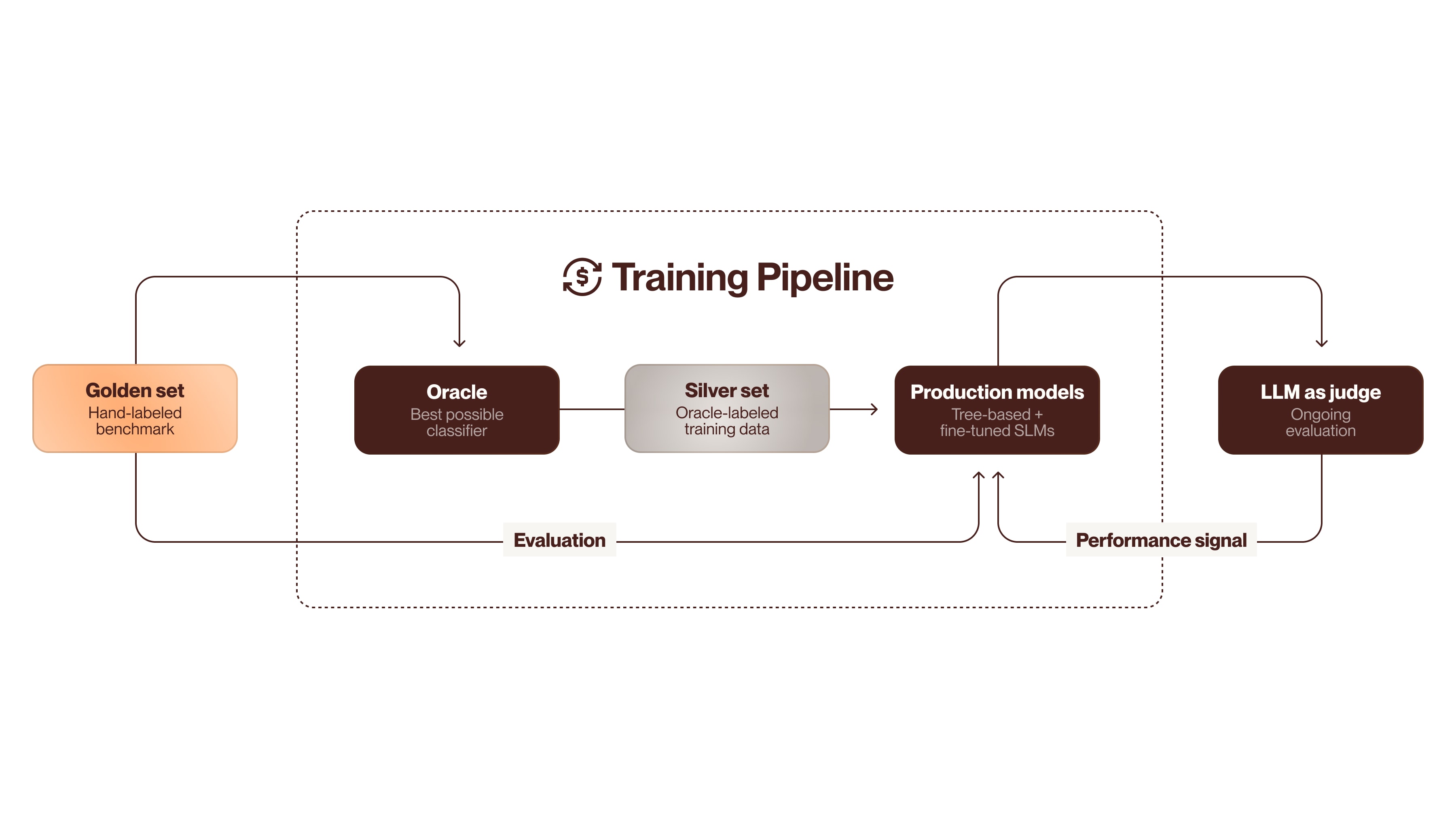
Our training pipeline uses a best-in-class model we call the oracle to generate silver-labeled data at scale, with evaluation against hand-labeled golden sets and LLM-based ongoing quality monitoring.
The temptation is to summarize the improvement with a single number: Between our previous approach and the current system, accuracy increased from 55% to 82%. But this comparison, while technically accurate, misrepresents the breadth of what changed.
The legacy system classified transactions against a less useful taxonomy, where categories were flat rather than hierarchical. Transfers landed in a catch-all, non-meaningful bucket simply called “excluded.” When that system achieved 55% accuracy, it was measuring how often transactions matched a flawed schema.
The new system classifies against a richer hierarchical taxonomy designed around what downstream systems actually need. Comparing 82% accuracy on this taxonomy to 55% on the old one isn’t apples to apples. The rebuild improved both the measure and the thing being measured: a more accurate system producing more useful outputs.
It’s also worth noting what the accuracy metric actually measures. Many enrichment systems categorize transactions by counterparty type—identifying that a purchase was made at a grocery store, for example. Cleo’s system accomplishes something harder, namely identifying the purpose of the transaction for the user. A grocery store purchase could be weekly essentials or a bottle of wine for dinner with friends. This distinction matters for an AI assistant reasoning about spending, but it makes the classification task significantly more difficult. The 82% figure reflects accuracy against a stricter standard.
The difference is evident at the level of individual transactions. Classifications that were previously nonsensical, such as credit disbursements labeled as income, now resolve correctly. The old system’s errors were clustered around predictable ambiguities that the new taxonomy and classification approach were specifically designed to address. The confusions that persist tend to occur at genuinely ambiguous boundaries, like dining versus takeout or household purchases versus groceries.
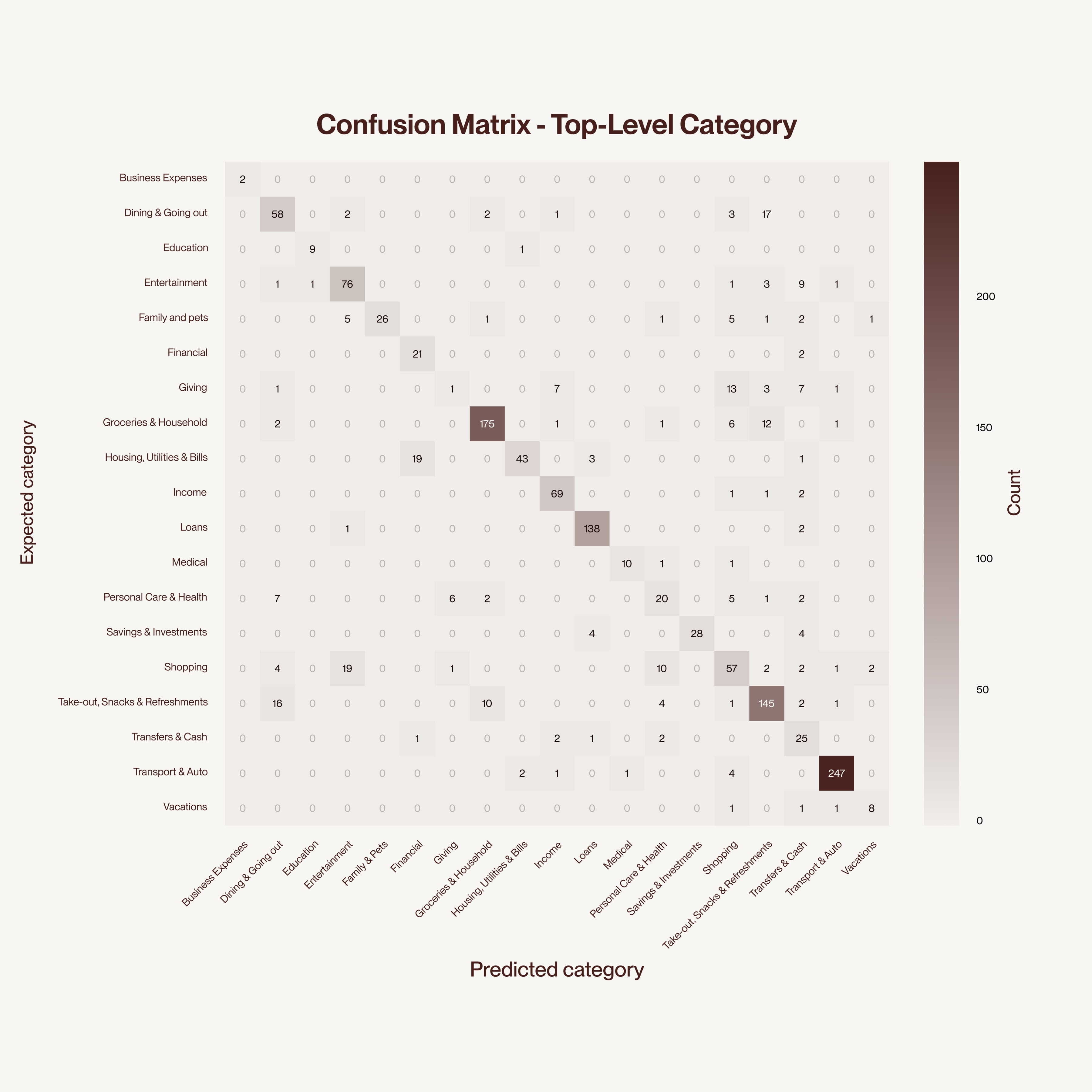
The confusion matrix shows strong diagonal performance across most top-level categories, with the model correctly classifying the vast majority of transactions. Residual confusion clusters at semantically ambiguous boundaries where even human labelers might reasonably disagree.
Transaction enrichment isn’t the flashiest part of an AI financial assistant, but it’s what makes everything else possible. These improvements propagate through every downstream system. Cleo’s agents receive structured, contextualized data rather than raw records, enabling them to reason about a user’s financial situation with fidelity that wasn’t previously possible. Likewise, confidence scoring helps these agents make more informed decisions under uncertainty by flagging ambiguity upfront.
For users, this means that Autopilot’s plans and recommendations are more helpful because they’re grounded in accurate data, reliably distinguishing income from transfers and recurring commitments from one-off purchases. Cleo can now go beyond the numbers to understand what your transactions really mean.
Today, we’re launching Autopilot: Cleo’s first step toward autonomous money management.

When extending Cleo’s chat engine to real-time voice, we needed to keep Cleo’s personality and tone while maintaining high accuracy and low latency.

Cleo’s quick replies only help if they arrive before users start typing, so we fine-tuned a specialized small model to reduce latency.

It’s part of a larger system that keeps message classification accurate as user behavior shifts and new agents come online.